Der Bibliothekartag in Berlin ist vorbei - mit vielen interessanten Vorträgen und Veranstaltungen, guten Gesprächen mit Kolleginnen und Kollegen und nicht zuletzt einem sehr gelungenen Rahmenprogramm. Ich habe von der Konferenz zahlreiche Anregungen und Aha-Effekte mitgenommen. Eines der "heißen" Themen dieses Bibliothekartags war zweifellos die maschinelle und computerunterstützte Sacherschließung. In diesem Blogbeitrag berichte ich ein wenig von drei Veranstaltungen, bei denen es ganz oder zum Teil um diese Themen ging, wobei ich gelegentlich hin und herspringen werde. Konkret geht es um den ersten Teil des LIS-Workshops am Dienstag nachmittag, das Hands-on Lab Bewertung maschineller Erschließung - Qualität ist kein Zufall am Mittwoch nachmittag sowie die öffentliche Arbeitssitzung der Erwerbungskommission mit dem Titel Metadaten zwischen Autopsie und Automatisierung - welche Qualität brauchen wir? am Donnerstag nachmittag.

Der Vortragsblock im LIS-Workshop bestand aus fünf Vorträgen; ich werde im Folgenden aber nur auf einen Teil davon näher eingehen. Das Hands-on Lab (für das man sich im Vorfeld anmelden musste, sodass eine vernünftige Teilnehmerzahl gewährleistet war) war eine hervorragend vorbereitete und umgesetzte Veranstaltung - ein großes Lob an das Vorbereitungsteam aus DNB und ZBW! Nach einem ersten Block mit Impulsvorträgen gab es im zweiten Teil die Möglichkeit, sich zum einen über die Qualitätsbewertung maschinell erzeugter Schlagwörter bei der ZBW zu informieren und zum anderen selbst einmal die an der DNB angewandte Methode zur Qualitätsbewertung auszuprobieren. Im dritten Teil diskutierten wir in Gruppen in Form eines World Café zu drei verschiedenen Themen: das Verhältnis von Mensch und Maschine, die Frage der Qualität und die Auswirkungen auf die Recherche.


Die Veranstaltung der dbv-Kommission für Erwerbung und Bestandsentwicklung zum Thema Metadatenqualität war als Follow-up zum Workshop in Düsseldorf vom März diesen Jahres (vgl. Blogbeitrag) gedacht. Nach einem Einführungsvortrag von Annette Klein (UB Mannheim), in dem vor allem die Ergebnisse aus Düsseldorf zusammengefasst wurden, gab es eine Podiumsdiskussion unter der Moderation von Jens Lazarus (ZBW). Außer mir nahmen daran noch Regine Beckmann (Stabi Berlin), Volker Conradt (BSZ Konstanz) und Olaf Schmalfuß (De Gruyter) teil. Im Gespräch ging es vielfach um strategische Fragen und Überlegungen, die sich nicht nur auf die Formal-, sondern auch auf die Sacherschließung bezogen.
Passend zu den einschlägigen Veranstaltungen auf dem Bibliothekartag wurde kurz davor außerdem noch eine Stellungnahme einer Initiativgruppe des Standardisierungsausschusses zur weiteren Entwicklung der
Inhaltserschließung im D-A-CH-Raum veröffentlicht, die man auf der Website der DNB nachlesen kann.
Maschinelle Verfahren bei der DNB
Erwartungsgemäß konzentrierte sich vieles auf die maschinellen Verfahren der DNB - insbesondere auf die maschinelle Vergabe von Schlagwörtern, die seit dem letzten Jahr nicht mehr nur für Online-Ressourcen angewendet wird, sondern auch für Printpublikationen der Reihen B und H. Für meinen eigenen Vortrag, dessen Folien bereits online stehen, habe ich eine größere Zahl von DNB-Titelaufnahmen der jüngeren Vergangenheit gesichtet und analysiert, wobei ich mich vor allem auf die Reihe B konzentriert habe. Im Mittelpunkt standen also recht heterogene Print-Materialien. In den meisten Fällen bildete - neben den Titelangaben - das Inhaltsverzeichnis die Basis für die maschinelle Verschlagwortung. Mein Ziel war es nun einerseits, häufig auftauchende Fehlertypen einmal systematisch anhand von Beispielen darzustellen, und andererseits, einige Überlegungen für mögliche Weiterentwicklungen anzustellen. Ich denke, dass die Folien auch für diejenigen einigermaßen verständlich sind, die nicht in Berlin sein konnten, sodass ich hier nicht alles wiederholen muss.
Zu meinem Vortrag passte besonders gut der von Karen Köhn: Maschinelle Sacherschließungsverfahren bei medizinischen Publikationen - Erfahrungen an der DNB. Auch davon stehen die Folien erfreulicherweise schon zur Verfügung. Hier ging es nicht nur um die verbale, sondern auch um die klassifikatorische Erschließung mit DDC-Sachgruppen und Kurznotationen bei Print-Publikationen aus dem Bereich Medizin. Die maschinelle Klassifikation funktioniert dabei merklich besser als die maschinelle Schlagwortvergabe: Die DDC-Sachgruppe 610 wurde in einem Testbestand von 1.650 Titeln immerhin zu 84,5 % richtig vergeben. Bei dem aus der Reihe H stammenden Anteil war der Wert sogar noch etwas höher (89,6 %), während er bei Medizin-Titeln aus der Reihe B deutlich absank (51,1 %). Das ist nicht wirklich verwunderlich, weil bei nicht-wissenschaftlicher Literatur sprachliche Phänomene wie reißerische Titel oder uneigentlicher Wortgebrauch, welche die maschinelle Einordnung erschweren, besonders häufig vorkommen. Bei der Vergabe der 140 DDC-Kurznotationen erreichte die Maschine immerhin noch eine Trefferrate von ca. 68 % (mit einer Schwankung von plus/minus 8 % bei den verschiedenen Notationen), wobei hier interessanterweise kein Unterschied zwischen den Reihen festzustellen war.
Betrachtet man hingegen die maschinelle Schlagwortvergabe, so ist das Ergebnis ernüchternd. Insgesamt 456 Titel wurden bewertet; sie teilten sich in vier Gruppen auf (Reihe A, Reihe A Diss, Reihe B, Reihe H). Die Fälle, in denen das Gesamtindexat mit sehr gut oder zumindest gut bewertet wurde, schwankte zwischen 26 % (Reihe A) und 44 % (Reihe H); der höchste Wert für "sehr gut" lag dabei bei 8 % (Reihe A). Die "mäßigen" Gesamtindexate bewegten sich zwischen 35 % (Reihe B) und 42 % (Reihe A), und die "unbrauchbaren" zwischen 16 % (Reihe H) und 32 % (Reihe A). Und dies, obwohl die Fachzuordnung offenbar bereits im Vorhinein feststand (was die Sache eigentlich erleichtern müsste, z.B. bei der Disambiguierung), und bei einem Fachgebiet, das als vergleichsweise dankbares Feld für maschinelle Verfahren gilt.
Beim Hands-on Lab wurde uns genau erklärt, wie die Bewertung der maschinell vergebenen Schlagwörter erfolgt. Es wird sowohl jedes einzelne Schlagwort bewertet als auch das Gesamtindexat. Für die Schlagwörter gilt die bekannte Skala von "sehr nützlich" ("beschreibt einen wesentlichen Aspekt des Textes ausreichend und trifft absolut zu") über "nützlich" (beschreibt einen wichtigen Aspekt des Textes aus einer etwas weiteren/engeren Perspektive zutreffend"), "weniger nützlich" ("beschreibt einen wichtigen Aspekt des Textes nicht ausreichend, ist aber auch nicht völlig unzutreffend oder falsch") bis zu "falsch" ("beschreibt keinen wichtigen Aspekt des Textes und ist falsch oder nicht nützlich"). Außerdem werden die im Indexat fehlenden Aspekte erfasst. Für das Gesamtindexat werden auf dieser Basis die Noten "sehr gut" ("ist vollständig und bildet den Inhalt/das Thema der Publikation vollständig ab"), "gut" ("ist nicht vollständig, enthält aber das/die wesentlichen Schlagwörter"), "mäßig" ("ist unvollständig und die Schlagwörter bilden den Inhalt/das Thema zu weit, zu eng oder nur zu einem Teil ab") oder "unbrauchbar" (bildet den Inhalt/das Thema nicht ab oder es wurden zu viele falsche Schlagwörter vergeben") vergeben.
Die TeilnehmerInnen konnten dies auch selbst an einigen Beispielen ausprobieren, wobei erwartungsgemäß recht unterschiedliche Ergebnisse herauskamen. Das lag allerdings sicher auch daran, dass die Bewertergruppe keine Gelegenheit hatte, im Vorfeld gemeinsam zu diskutieren, wie bestimmte Fälle eingeordnet werden sollten. Ein gutes Beispiel dafür ist der Titel "Lust auf NaTour : Brandenburgs Großschutzgebiete erleben" (http://d-nb.info/1139899805). Nach RSWK würde man auf die Nennung einzelner Naturparks etc. verzichten, die Maschine hat allerdings vier der insgesamt 15 genannten Schutzgebiete als Schlagwort ausgeworfen. Die Bewertung dieser Schlagwörter durch die Workshop-TeilnehmerInnen schwankte zwischen "sehr nützlich" und "weniger nützlich". Interessant wäre nun die Frage, ob es weiterhin zu so unterschiedlichen Bewertungen kommt, nachdem man sich über die Einordnung solcher Typen grundsätzlich verständigt hat - hier gab es ja sicher auch viele Diskussionen in der DNB. Die DNB-KollegInnen erwähnten bei der Gelegenheit auch, dass die dritte Bewertungsstufe ("weniger nützlich") besonders schwierig zu handhaben sei.
Bei den Gesprächsrunden im World Café wurden - neben vielen anderen Dingen - auch die Auswirkungen von schlechten Schlagwörtern diskutiert. U.a. wurde die Frage aufgeworfen, ob evtl. völlig falsche Schlagwörter weniger schädlich seien als zu weite bzw. zu allgemeine Begriffe. Es wurde auch überlegt, welche Menge an falschen Schlagwörtern noch vertretbar sei. Ein interessanter Hinweis war auch, dass bei schlechten Schlagwörtern die Arbeit eigentlich auf die NutzerInnen verlagert werde, weil diese dann den Aufwand haben, unpassende Titel aus ihrer Trefferliste auszusortieren. Bei den "weniger nützlichen" Schlagwörtern wurde vermutet, dass sie in der Anzeige weniger Schaden verursachen als bei der Recherche, wo sie wohl für erheblichen Ballast sorgen. Jedoch wurde auch darauf hingewiesen, dass die Anzeige ersichtlich falscher Schlagwörter einen Vertrauensverlust der NutzerInnen zur Folge haben könnte.
Und noch ein interessanter Gedanke, der mir im Gedächtnis geblieben ist: Im Vortrag Automatisierte Sacherschließung: Vergabe von Notationen der Regensburger Verbundklassifikation (RVK) von Konstantin Hermann (SLUB Dresden) und Torsten Hartmann (Avantgarde Labs) im LIS-Workshop wurde ausgeführt, dass ja auch menschliche ErschließerInnen Fehler machen würden; die Maschine wäre bei ihren Fehlern zumindest konsistent. Im Workshop arbeiteten wir jedoch heraus, dass Menschen ganz andere Fehler machen als Maschinen - und diese Fehler für die NutzerInnen deutlich weniger schwerwiegend sind als die Missgriffe, zu denen es bei den automatischen Verfahren kommen kann. Ich kann das aus meiner Analyse im Vorfeld des Vortrags bestätigen: Ich habe dabei auch immer geschaut, ob es zu den fraglichen Titeln irgendwo eine intellektuelle Erschließung gibt. Dabei habe ich zwar öfter Schlagwortfolgen gesehen, die nicht ganz RSWK-gerecht waren, aber niemals ein inhaltlich völlig verkehrtes Schlagwort.
Maschinelle Indexierung an der ZBW
Sehr erhellend war für mich die Demonstration des Bewertungstools für maschinelle Indexierung an der ZBW, ebenfalls im Rahmen des Hands-on Lab. Zwar war bei den Demo-Beispielen natürlich auch nicht alles richtig, aber die Ergebnisse bewegten sich dennoch auf einem deutlich besseren Niveau als bei der DNB-Methode. Dafür scheint es mehrere Ursachen zu geben: Zum einen ist die bearbeitete Literatur natürlich längst nicht so heterogen wie etwa die Publikationen in der Reihe B. Abgeglichen wird auch nicht mit der thematisch extrem breiten GND, sondern mit einem Fachthesaurus, dem Standard-Thesaurus Wirtschaft (STW). Logischerweise kommen viele Probleme gar nicht zum Tragen, etwa bei der Zuordnung des richtigen Konzepts. Ein simples Beispiel: Der STW kennt "Bank" nur in der Bedeutung "Kreditinstitut" und nicht auch noch in der Bedeutung "Sitzgelegenheit" - also kann es hier keine Verwechslung geben. Anders als in der GND kommen im STW, soweit ich sehe, auch keine "Named entitities" vor, die der Averbis-Software so große Schwierigkeiten bereiten (vgl. meinen Vortrag). Weitere Vorteile ergeben sich vermutlich daraus, dass als Basis normalerweise ein Abstract verwendet wird und nicht ein Inhaltsverzeichnis. [Nachtrag vom 18.06.: Dies war ein Missverständnis von mir; siehe den Kommentar von Herrn Rebholz und Herrn Kempf unten an diesem Beitrag. Nur der Titel und die Autorenkeywords werden für die Ermittlung der Schlagwörter herangezogen.]
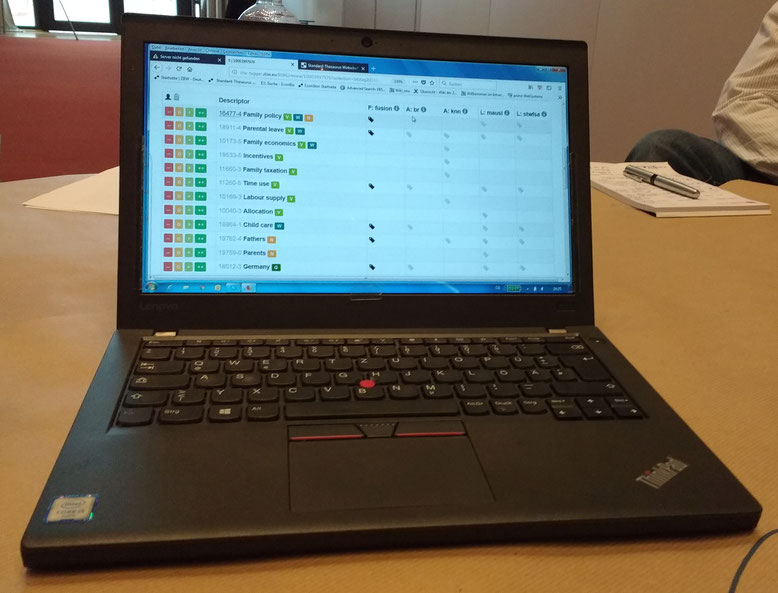
Zweitens setzt man bei der ZBW bewusst nicht nur auf eine Karte, sondern es laufen vier (!) verschiedene Verfahren gleichzeitig. In das sogenannte Hauptindexat werden nur diejenigen Indexterme aufgenommen, die von mindestens zwei Verfahren ausgeworfen wurden. Man kann das vielleicht auf meinem Foto des ZBW-Bewertungstools auf dem Demo-Notebook erahnen: Die vier Spalten rechts zeigen die Ergebnisse der einzelnen Verfahren, jeweils mit grauen Labeln für die erkannten Deskriptoren. In der fünften Spalte von rechts (betitelt als "fusion") sind diejenigen Terme mit einem schwarzen Label gekennzeichnet, die mindestens zweimal erkannt wurden. Damit werden sozusagen "Ausrutscher" einzelner Verfahren ausgefiltert.
Computerunterstützte Sacherschließung
Auch bei der computerunterstützen Erschließung wurden auf dem Bibliothekartag Neuerungen vorgestellt. Regine Beckmann (Stabi Berlin) und Imma Hinrichs (UB Stuttgart) präsentierten die dritte Generation des sogenannten "Digitalen Assistenten", der noch in diesem Jahr im GBV und SWB eingeführt werden soll. Das Grundprinzip ist weiterhin, dass die menschlichen ErschließerInnen die volle Gewalt über ihre Erschließungen behalten, aber in vielfältiger Weise bei ihrer Arbeit unterstützt werden. Beispielsweise nimmt das System ihnen die Recherchen in unterschiedlichen Katalogen ab und sucht automatisch bereits vorhandene Sacherschließungsinformationen zusammen (wobei auch Sacherschließung aus Fremdsystemen wie den LCSH in Form von "approximativen Übersetzungen" ausgewertet wird). Es sind auch keine Wechsel mehr zwischen unterschiedlichen Plattformen nötig, sondern alles kann sehr komfortabel direkt im DA erledigt werden (mit Ausnahme der Ansetzung neuer Schlagwörter in der GND). Das freut viele, die das Arbeiten in der WinIBW als sperrig und umständlich empfinden. Im Vergleich zum DA-2 verfügt der DA-3 über verbesserte und erweiterte Funktionalitäten; u.a. kann man damit auch RVK und BK vergeben.
In der Podiumsdiskussion der Erwerbungskommission wurde in diesem Zusammenhang gefragt, wie hoch die Zeitersparnis durch den DA sei. Wie Tests an der Staatsbibliothek zu Berlin gezeigt haben, liegt diese bei ca. 50 %, was ich schon für eine gewaltige Verbesserung halte. Die von einem Kollegen geäußerte Befürchtung, dass der DA die Erschließenden zu bloßen "Abnickern" degradieren könnte, halte ich für unbegründet. Nach meinem Eindruck ist es eher so, dass einem die lästigen, eher mechanischen Arbeiten abgenommen werden, und man dadurch den Kopf frei bekommt für den eigentlichen Kern der Erschließungsarbeit. Ich jedenfalls hätte mir in meiner Zeit als Fachreferentin genauso ein Tool gewünscht.
Auf dem LIS-Workshop wurde - in dem weiter oben schon genannten Vortrag aus Dresden - noch ein weiteres Werkzeug für die computerunterstützte Erschließung vorgestellt, das sich allerdings noch in der Pilotphase befindet und ausschließlich auf die Vergabe von RVK abzielt. Wenn ich es richtig verstanden habe, liegen die Neuerungen weniger im eingesetzten Klassifikator, sondern vor allem in einem schnell und komfortabel zu bedienenden Werkzeug. Man erhofft sich dadurch einen erheblichen Zeitgewinn und die Möglichkeit, auch Ressourcen mit RVK zu erschließen, die bisher nicht systematisiert wurden. Besonders betont wurde, dass die RVK-Erschließung schon bei der Bestellung erfolgen solle, da die SLUB Dresden großen Wert auf eine "shelf-ready"-Lieferung lege. Es wäre aber, wie Torsten Hartmann von der Partnerfirma Avantgarde erläuterte, auch möglich, bei einer autoptischen Erschließung z.B. einzelne Seiten abzufotografieren und als zusätzliche Basis für die zu generierenden Vorschläge zu verwenden. Hier entspann sich auch eine kurze Diskussion darüber, ob die Software als Open Source zur Verfügung gestellt werden könnte - dies wurde grundsätzlich bejaht.
Strategie
Ich beschließe diesen (bereits viel zu langen) Blogbeitrag mit einigen Hinweisen zu strategischen Fragen, die auch auf der Podiumsdiskussion zur Sprache kamen. Regine Beckmann betonte zu Recht, dass es unser Ziel sein müsse, alle Ressourcen auch sachlich zu erschließen. Die DNB hat hier ja die Vorstellung entwickelt, dies mithilfe der maschinellen Erschließung umfassend und gleichmäßig erreichen zu können. Dies wäre jedoch nach meiner Ansicht nur dann denkbar, wenn die Ergebnisse der maschinellen Erschließung sich dramatisch verbessern würden - womit nach meinem Eindruck in absehbarer Zeit nicht zu rechnen ist.
Umso wichtiger ist es deshalb, mehrgleisig zu verfahren, um zum bestmöglichen Gesamtergebnis zu gelangen. Der Einsatz von computerunterstützten Systemen ist sicher nicht die einzige Lösung, reduziert aber den Aufwand für die intellektuelle Erschließung erheblich. Entsprechend können in derselben Zeit größere Mengen an Ressourcen intellektuell erschlossen werden. Als weitere Idee wurde in den Diskussionen eine bessere Nachnutzung von intellektueller Erschließungsleistung genannt. Dazu gehört auch die "Übersetzung" bzw. das Mapping zwischen unterschiedlichen Erschließungssystemen. In diesem Bereich wurde in der Vergangenheit manches per Handarbeit geleistet, was jetzt z.B. der DA ausnützt (man denke an das MACS-Projekt, wo GND, LCSH und Rameau aufeinander gemappt wurden); Konkordanzen können jedoch auch maschinell erstellt werden. Ebenso gehört ein umfassendes Werk-Clustering dazu, um alle Ausgaben eines Werks mit sämtlicher an irgendeiner Manifestation vorhandenen Sacherschließungsinformation anzureichern. Dies ist keine neue Idee: In einigen Verbünden wurde es schon sehr erfolgreich in Form einer Batch-Verarbeitung mit der "Methode Pfeffer" umgesetzt. Angela Vorndran (DNB) erläuterte in ihrem Vortrag Hervorholen was in unseren Daten steckt! Mehrwerte durch Analysen großer Bibliotheksdatenbestände, dass ein solcher Abgleich über die Culturegraph-Plattform künftig sozusagen laufend möglich sei - dies wäre eine erhebliche Verbesserung.
Ein weiteres zentrales Standbein muss eine bessere Abstimmung zwischen den "Playern" und eine einigermaßen verbindliche Regelung sein, welche Bibliothek für welches Segment zuständig ist. Vielfach liegt eine besondere Verantwortlichkeit für bestimmte Bereiche ja auf der Hand, z.B. bei FID-Bibliotheken oder Regionalbibliotheken. Darauf könnte man aufbauen und zu einem wirklich arbeitsteiligen System gelangen, das besser funktioniert als unser heutiges "Nebeneinander" in der Erschließung. In denselben Zusammenhang gehört auch die Entwicklung von Kriterien - einerseits dafür, welche Erschließungsqualität für welche Materialien benötigt wird (was ist der "Kern", für den eine hohe Qualität unbedingt erforderlich ist, und wofür genügt eine schlechtere maschinelle Erschließung?), andererseits dafür, welches Erschließungssystem wofür am besten geeignet ist. Mir scheint, dass für viele Ressourcen eine klassifikatorische Basiserschließung durchaus ausreichend wäre, zumal die maschinelle Klassifikation scheinbar besser funktioniert als die maschinelle Schlagwortvergabe.
Vor diesem Hintergrund begrüße ich die bereits erwähnte Stellungnahme einer Initiativgruppe des Standardisierungsausschusses zur weiteren Entwicklung der Inhaltserschließung im D-A-CH-Raum sehr, denn sie geht genau in die richtige Richtung.
Und damit beschließe ich nun diesen Blogbeitrag und freue mich auf Ihre Ergänzungen und Diskussionsbeiträge über die Kommentarfunktion.
Heidrun Wiesenmüller
Kommentar schreiben
Tobias Rebholz (Montag, 18 Juni 2018 12:48)
Liebe Frau Wiesenmüller,
herzlichen Dank für Ihre Teilnahme an unserem Hands-On Lab und ihre positive Herausstellung der Veranstaltung in Ihrem Beitrag.
Wir freuen uns, dass es uns gelungen ist, in einem neuen Veranstaltungsformat einen tieferen Einblick in die Arbeitsweise unseres Ansatzes der maschinellen Indexierung zu geben und dass unsere Ergebnisse insgesamt überzeugen konnten.
In diesem Zusammenhang möchten wir noch einmal hervorheben, dass die maschinelle Sacherschließung in der ZBW derzeit ausschließlich auf Titeln und Autoren-Keywords beruht. Um im Rahmen der qualitativen Bewertung schnell in das Thema des jeweiligen Beispiels einzusteigen, werden -sofern vorhanden und rechtlich unkritisch- zusätzlich Abstracts angezeigt. Diese dienen somit als eine zusätzliche Bewertungsgrundlage im Qualitätsmanagement und werden aktuell nicht zur Indexierung durch die Verfahren herangezogen.
Mit freundlichen Grüßen
Tobias Rebholz und Andreas Kempf
ZBW - Leibniz-Informationszentrum Wirtschaft (Kiel/Hamburg)
Gerald Langhanke (Mittwoch, 20 Juni 2018 13:37)
Liebe Frau Wiesenmüller,
ein Gesichtspunkt, der mir immer zu wenig vorkommt, ist, dass in den heutigen Discovery-Systemen ja nicht nur die Schlagworte der Inhalts-Recherche dienen, sondern ganz massiv auch gescannte Inhaltsverzeichnisse (IVs) als ganzes.
Ich stelle mir da die Frage: Welchen Mehrwert bringt ein maschinelles Verfahren, das aus dem IV einzelne GND-Begriffe zu extrahieren versucht, dabei aber nichts inhaltlich neues beiträgt und häufig beliebige Einzelaspekte aus dem IV verstärkt? -> Dann lieber gar keine Schlagworte!
Viele Grüße,
Gerald Langhanke
ULB Darmstadt
Bernhard Eversberg (Sonntag, 22 Juli 2018 13:07)
Hallo Frau WIesenmüller,
vielen Dank für den ausführlichen Bericht und die sehr gute Präsentation.
Das Scheitern des Ansatzes bei DNB war voraussehbar. Spätestens seit den sprachphilosophischen Arbeiten von Frege und Wittgenstein ("Nur im Zusammenhang eines Satzes hat ein Wort Bedeutung") konnte man wissen oder ahnen, daß Algorithmik kein probates Mittel ist zur Erschließung eines sprachlichen Inhalts, und zumal eines bloßen Titels. Chomsky hat gleichwohl postuliert, es gebe eine "angeborene Grammatik", dank derer jedes Kleinkind eine beliebige Sprache lernen kann, und wenn man die nur herausfände, könnte man jede Sprache algorithmisch in jede andere übersetzen. Die relativ erfolgreichen Ansätze von "Google Translate" und "DeepL" beruhen denn auch auf ganz anderen Methoden: BigData und Statistik statt abstrakte, nur auf Syntax schielende Algorithmik. Die Beispiele, die Sie geben, erhellen das für jeden, der's noch nicht geglaubt hat.
In dieser Richtung hatte ich auch mal ein Papier geschrieben, betitelt "Eine seltene Sache". Aus diesem Titel auf den Inhalt zu schließen, war gleichfalls unmöglich, deshalb war noch ein Titelzusatz beigefügt. Auch aus diesem wäre noch immer nicht das Schlagwort "Sacherschließung" algorithmisch zu erschließen.
Im Übrigen aber meine ich, DNB sollte automatisch erzeugte Schlagwörter nicht ohne Redaktion an die Öffentlichkeit gelangen lassen. Daß es von deren Seite noch keine entrüsteten, höhnischen oder belustigten Kommentare gegeben hat - was soll man daraus schließen?
Schönen Gruß
B.Eversberg
Heidrun Wiesenmüller (Sonntag, 22 Juli 2018 19:23)
Lieber Herr Eversberg,
danke für den Hinweis auf Ihren damaligen Text - den werde ich mir nochmal ansehen. Ich bin übrigens gerade dabei, meinen Vortrag für den Kongressband zum Berliner Bibliothekartag (der wieder in o-bib erscheinen wird) auszuformulieren. Einige der ganz kuriosen Schlagwörter in den von mir herausgesuchten Beispielen wurden übrigens mittlerweile aus den Katalogisaten entfernt ;-)
Viele Grüße
Heidrun Wiesenmüller
Gerald Langhanke (Dienstag, 07 August 2018 10:13)
Liebe Frau Wiesenmüller,
wollen sie irgendwo eine interaktive Seite einrichten, wo der haarsträbendste SE-Unsinn der DNB gesammelt wird? Mein Favorit der Woche: http://d-nb.info/1161144811
Viele Grüße,
Gerald Langhanke