Bei einem der Fokusgruppengespräche, die ich derzeit führe (vgl. den Blog-Beitrag), kamen wir auf die optionale Weglassung bei Verantwortlichkeitsangaben mit mehr als drei Personen etc. in gleicher Funktion RDA 2.4.1.5). Jemand fragte: "Schreibt man da jetzt eigentlich 'und ... andere' oder 'und ... weitere'?" Die Beispiele in der deutschen Übersetzung (siehe Screenshot) sind uneinheitlich: Einmal heißt es "[und sechs weitere]" und einmal "[und 4 andere]". Übrigens steht im Englischen in beiden Fällen "others" ("[and six others]" bzw. "[and 4 others]"). Aber ich finde es gar nicht schlecht, dass die deutsche Übersetzung hier zwei unterschiedliche Varianten zeigt - denn dadurch wird deutlich, dass es sich eben nicht um eine normierte Formulierung handelt, die man exakt kopieren müsste. Vielmehr kann man es machen, wie man will, also sozusagen "halten wie ein Dachdecker" (zur Herkunft der Redewendung siehe Wikipedia). Frau Horny und ich fanden "und andere" im Deutschen gefälliger als "und weitere", weshalb wir im Lehrbuch diese Variante vorgezogen haben.

Beispiele: illustrativ, nicht präskriptiv
So weit, so gut. Zu großem Erstaunen führte es in der Gruppe aber, als ich sagte: "Sie müssen nicht einmal zählen, wieviele Personen Sie weggelassen haben!" Das war für alle neu.
Es ist aber wirklich so. Denn die Beispiele in RDA sind grundsätzlich illustrativ und nicht präskriptiv. Das heißt, sie zeigen eine oder mehrere Möglichkeiten, wie man die jeweilige RDA-Regel korrekt anwenden kann ("illustrativ"). Dies bedeutet aber nicht, dass es nicht auch noch weitere Möglichkeiten geben kann, die ebenfalls korrekt sind. Es wird also nicht vorgeschrieben, dass man es genau so machen muss wie im Beispiel - das wäre "präskriptiv". Entscheidend dafür, ob eine Lösung RDA-gerecht ist oder nicht, ist vielmehr nur der Text der Regelwerksstelle. Die Beispiele sollen die Regel also wirklich nur illustrieren und nicht als Ersatz für sie dienen. Man kann dies im RDA examples guide nachlesen (Stand November 2014, S. 3):

Prüfen wir daraufhin noch einmal unser Beispiel: Im Text selbst wird nur verlangt, dass man das, was man weggelassen hat, zusammenfassend wiedergibt. Es steht aber definitiv nicht da, dass man dafür die genaue Zahl der weggelassenen Personen etc. angeben müsste. Gerade bei einer längeren Liste von Namen könnte man also genauso gut schreiben: "[und viele andere]". Dies erfüllt die Anforderung von RDA, spart Zeit und wird den BenutzerInnen gewiss nicht schaden. Denen dürfte es herzlich egal sein, ob es 37 oder 38 Beiträger waren, während Sie beim Katalogisieren die Liste womöglich sogar zweimal durchzählen würden, um nur ja keinen Fehler zu machen.
Wir müssen uns also grundsätzlich umgewöhnen, denn unter RAK hatten die Beispiele eine ganz andere Bedeutung. Den eigentlichen Regelwerkstext hat man zwar vielleicht gelesen (und nicht immer gut verstanden). Aber das Entscheidende war, bei den Beispielen etwas zu finden, was auf den eigenen Fall passte - dieses Beispiel hat man dann genau nachgemacht. Beispiele in RAK wurden also wirklich als präskriptiv verstanden, und waren vermutlich auch so gemeint.
Lokalisierung der Beispiele
Es gibt noch einen zweiten Punkt, warum wir uns nicht sklavisch an die Beispiele halten sollten: Sie wurden bei der Übersetzung weitgehend unverändert aus der englischsprachigen Vorlage übernommen. In der Softwareentwicklung gibt es das Konzept einer sogenannten Lokalisierung, d.h. der Anpassung eines Produkts in sprachlicher und kultureller Hinsicht für die Nutzerschaft in einem bestimmten geografischen Raum. Eine solche Lokalisierung fand natürlich schon statt, weil man Deutsch anstatt Englisch verwendete. Aber ansonsten wurde bei der Übersetzung nicht darauf geachtet, ob die Beispiele insgesamt zu unseren Gepflogenheiten passen oder nicht. Insofern handelt es sich nur um eine recht oberflächliche Lokalisierung.
Dies wurde übrigens ganz bewusst so gehalten. Auf ihrer 12. Sitzung im März 2014 diskutierte die AG RDA über das Thema. Im Protokoll gibt es nähere Informationen zum Konzept der Übersetzung (TOP 5, S. 6). Die Übersetzerin wies darauf hin, "dass zwar der Standardisierungsausschuss Deutsch als Arbeitssprache beschlossen hat, dass aber von Anfang an dem Prinzip gefolgt wurde, eine deutsche Übersetzung des Regelwerkstextes und keine deutsche Ausgabe/Version von RDA zu erstellen." Zwar ermögliche - so argumentierte sie weiter - der Übersetzungsvertrag unter bestimmten Bedingungen "minor modifications as needed to prepare the translation in accordance with local practice". Doch bei einer vollständigen Lokalisierung wäre es damit nicht mehr getan, "da an vielen Stellen Weglassungen, Ergänzungen oder der Tausch von Beispielen notwendig wären. Auch müsste die komplette Transliterationspraxis angepasst werden. Der Aufwand dafür wäre auf unserer Seite [der DNB, HW] relativ hoch, und es wäre künftig kaum mehr nachvollziehbar, an welchen Stellen im Standard selbst diese Änderungen vorgenommen wurden."
Freilich kann man es durchaus auch anders machen, wie unsere französischen und kanadischen Kolleginnen und Kollegen bewiesen haben. Bei ihrer Übersetzung schlugen sie nämlich den Weg einer vollständigen und konsequenten Lokalisierung des Regelwerks ein. Im Vorwort zur französischen Übersetzung im Toolkit heißt es dazu:
"La traduction vise à adapter ce code de catalogage aux bibliothèques et aux agences de catalogage de langue française, et non à se limiter à une traduction littérale de RDA, l’objectif étant de rendre disponible un code fonctionnel. Les références aux textes de l’IFLA disponibles en français sont donc données dans cette langue. De même, les manuels de style donnés en exemple dans le chapitre 1 sont conçus pour les francophones. Plus fondamentalement, certaines instructions telles que celles du chapitre 1 portant sur les chiffres ont dû être adaptées à l’usage français et tous les exemples ont été revus afin d’être en conformité avec un catalogue de langue française. Bien qu’ait prévalu un souci constant de garder le texte français au plus près de l’original, quelques exemples qui n’ont pu être adaptés ont été omis et d’autres exemples ont été ajoutés. (...)"
In der AG RDA wurde damals ein Meinungsbild dazu eingeholt, ob das ursprüngliche Konzept der deutschen Übersetzung beibehalten werden solle oder ob die Beispiele stattdessen vollständig an die deutschsprachige Praxis angepasst werden sollten. Eine sehr deutliche Mehrheit sprach sich dafür aus, die Beispiele konsequent zu lokalisieren - obwohl dies natürlich in der Tat einen erheblichen Aufwand bedeuten würde.
Bisher ist diese Umarbeitung allerdings noch nicht angegangen worden; sicher wäre zunächst auch das Votum des Standardisierungsausschusses einzuholen. Entsprechend lautet die Aussage in RDA 0.10 unverändert: "Alle Beispiele illustrieren Elemente in der Form, wie sie von einer Agentur erfasst würden, deren bevorzugte Sprache Englisch ist." Dies ist so natürlich nicht richtig, denn dann müsste beispielsweise bei der oben zitierten optionalen Weglassung "[and six others]" bzw. "[and 4 others]" in den Beispielen stehen. Denn gemäß der Regelwerksstelle sind derartige Zusammenfassungen in der Arbeitssprache zu machen - und diese wäre dann ja Englisch und nicht Deutsch. Ein bisschen kurios ist die Situation derzeit also schon.
Beispiele für Beispiele
In der Praxis gab es jedoch seit dem ersten Erscheinen der deutschen Übersetzung schon an zahlreichen Stellen Verbesserungen bei der Lokalisierung der Beispiele. Mir fällt z.B. RDA 6.3.1.3 ein ("Erfassen der Form des Werks"). Hier war ursprünglich ohne Rücksicht auf die Vorzugsformen der GND übersetzt worden, etwa im ersten Beispiel "play" mit "Schauspiel". Im zugehörigen D-A-CH wurde aber festgelegt: "Erfassen Sie die Form des Werks als normierten Sachbegriff aus der GND, sofern sich dieser leicht ermitteln lässt." Die Beispiele wurden mittlerweile daraufhin überprüft und ggf. abgeändert, sodass sie jetzt der GND entsprechen. Deshalb steht im ersten Beispiel seit August 2014 nicht mehr "Schauspiel", sondern "Drama".
Erst vor kurzem ist mir eine Stelle aufgefallen, an der die Beispiele unaufwendig an die deutschsprachige Praxis angepasst werden könnten und sollten. Beim Erfassen der Bezugsbedingungen (RDA 4.2.1.3) steht bei den Preisangaben das Währungssymbol immer ohne Leerzeichen unmittelbar vor dem Betrag:

Dies entspricht der üblichen angloamerikanischen Praxis, aber nicht der Vorgabe aus dem D-A-CH zu RDA 1.7.3. Dort heißt es unter Punkt 8: "Nach bzw. vor einem Zeichen, das ein Wort vertritt (z. B. §, ©, %, &), steht ein Leerzeichen (Ausnahme: Strich für "bis", s. AWR 1 Punkt 5b)." Ich habe im Wiki der AG RDA einen entsprechenden Änderungswunsch für die Übersetzung vermerkt und hoffe, dass die fehlenden Leerzeichen zum August-Update eingefügt werden.
Bleiben wir noch kurz bei RDA 1.7.3 (Zeichensetzung). Mehr als unglücklich bin ich mit dem letzten Beispiel im gelben Kasten:

Daraus schließt man ja fast zwangsläufig, dass Anführungszeichen exakt in der typografischen Form zu übertragen sind, in der sie in der Informationsquelle stehen. Im zugehörigen D-A-CH haben wir aber genau dies ausgeschlossen. Denn wir haben uns aus guten Gründen dafür entschieden, keine fotografisch exakte Abbildung anzustreben. Folglich haben wir jetzt im Regelwerkstext und im D-A-CH für dieselbe Sache zwei exakt gegensätzliche Beispiele:

Zwar sollte klar sein, dass in einem solchen Fall die D-A-CH-Regelung vorgeht, dennoch ist dies eine sehr unbefriedigende Situation, die sicher öfter zu Verwirrung führt. Besonders bitter ist, dass das fragliche Beispiel nach meinem Kenntnisstand ausgerechnet auf einen Fast track aus Deutschland zurückgeht. In der englischen Fassung des Toolkits erschien das neue Beispiel im Februar 2014. Vermutlich war der Fast track zu einem Zeitpunkt eingereicht worden, als sich die AG RDA noch gar nicht näher mit dem Thema Interpunktion beschäftigt hatte; leider war er vorab auch nicht in der AG RDA besprochen worden.
Eine denkbare Lösung für das Problem wäre nun, das Beispiel durch ein anderes auszutauschen, bei dem es nicht um Anführungszeichen, sondern um Klammern geht. Denn mit Ausnahme von eckigen Klammern werden diese nach unserer D-A-CH-Regelung exakt wiedergegeben. Man könnte also das, was hier illustriert werden soll - eine exakt vorlagegetreue Wiedergabe von Interpunktionszeichen - gut mit einem Beispiel erreichen, das eine spitze oder geschweifte Klammer enthält (hat jemand zufällig ein gutes Beispiel dafür?). Natürlich wäre dies dann eine größere Änderung gegenüber dem Original.
Übrigens sehe ich gerade, dass wir auch das D-A-CH zu 1.7.3 nochmals anfassen müssen (stöhn...). Denn in der rechten Tabellenspalte sollen beim zweiten und dritten Beispiel eben gerade keine typografischen Anführungszeichen stehen, sondern gerade. Ich habe das schon einmal korrigieren lassen. Warum dieses Detail offenbar mit dem Februar-Update nun wieder verloren gegangen ist, ist mir ein Rätsel. Aussehen muss es jedenfalls so:

Schauen wir uns noch einen weiteren Fall an, bei dem die Beispiele merklich verändert werden müssten, um der deutschen Praxis zu entsprechen - RDA 9.4.1.4.1 (Person mit dem höchsten fürstlichen Rang innerhalb eines Landes usw.):

Die hier aufgeführten Beispiele passen leider nicht auf unsere Anwendung: Denn wir erfassen den Titel der Person und den Namen des Landes bzw. Volkes nicht - wie in der angloamerikanischen Welt üblich - als eine einzige Phrase, sondern als zweiteilige, mit einem Komma getrennte Angabe (vgl. D-A-CH zu RDA 9.4.1.4). Für uns passende Beispiele zeigt die zugehörige Erfassungshilfe (EH-P-08) mit Angaben wie "Bayern, König" oder "Russland, Zar" im entsprechenden Unterfeld:
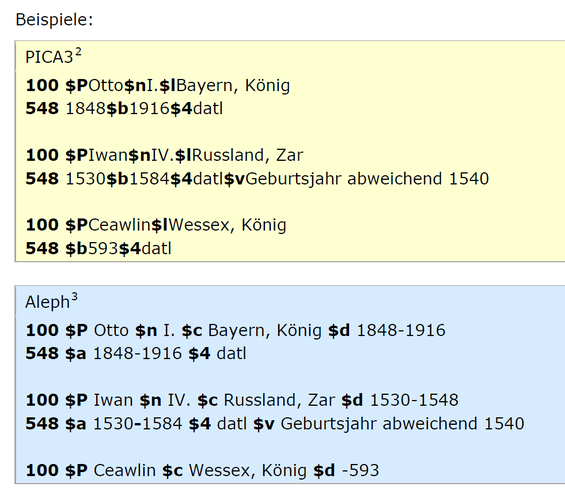
Auch diese Methode ist RDA-gerecht, da sie mit dem Regelwerkstext übereinstimmt. Denn dieser besagt nur, dass die beiden Informationen (Titel und Land/Volk) anzugeben sind, schreibt aber nicht vor, dass dies in Form einer Phrase zu geschehen hat. Bei einer umfassenden Lokalisierung von RDA müssten diese Beispiele folglich entsprechend angepasst werden, um unsere eigene Praxis zu illustrieren.
Beispiele in D-A-CH
Anders als bei den Beispielen im Regelwerkstext selbst, können Sie natürlich bei den Beispielen in den D-A-CH grundsätzlich davon ausgehen, dass sie der deutschsprachigen Anwendungspraxis entsprechen. Die D-A-CHs sind auch deutlich konkreter als der Regelwerkstext und machen genaue Vorgaben dazu, welche Möglichkeit(en) bei der Erfassung eines bestimmten Elements zulässig sind.

Beispielsweise steht in der RDA-Regel 7.13.2.4 (Details zur Schrift) letztlich nur, dass man solche Zusatzinformationen zur Schrift bzw. den Schriften erfassen kann - aber nicht, wie man das tun soll. Die zugehörige D-A-CH-AWR legt u.a. fest, dass man für die Namen der Schriften eine genormte Liste verwendet. Nicht exakt vorgeschrieben sind jedoch die genauen Formulierungen. Es ist zwar gewiss keine schlechte Idee, sich auch dafür an den Beispielen in den D-A-CH zu orientieren (immerhin wurde diese von der AG RDA geprüft und für gut befunden), aber man könnte eine solche Angabe jederzeit auch etwas anders schreiben. Wichtig ist also auch bei der Arbeit mit den D-A-CH, nicht nur auf die Beispiele zu schauen, sondern auch den zugehörigen Text zu lesen. Dieser gibt explizit an, für welche Aspekte es eine Vorgabe gibt und wie diese genau aussieht.
Damit bin ich nun alles zum Thema "Beispiele" losgeworden, was mir gestern abend vor dem Einschlafen so durch den Kopf gegangen ist (ja, ich gebe zu, dass mich RDA manchmal bis ins Bett verfolgt...). Ich bin gespannt, ob es auch diesmal wieder eine eifrige Diskussion in den Kommentaren gibt!
Heidrun Wiesenmüller
Kommentar schreiben
Hanke Immega (Montag, 06 Juni 2016 10:27)
Vielen Dank für diese Hinweise, besonders für die Beispiele zu den Beispielen! Damit können wir ja auch guten Gewissens in der Verantwortlichkeitsangabe "von Heidrun Wiesenmüller [und 39 anderen]" schreiben - und ggf. sogar "[und vielen anderen]" - und müssen nicht (wie schon öfter gesehen) der deutschen Grammatik Gewalt antun, indem wir beispielgetreu schreiben: "von Heidrun Wiesenmüller [und 39 andere]"!
Dr. Kai Multhaup (Montag, 06 Juni 2016 17:27)
Das mit den "anderen" (oder "weiteren" . . ?) sieht man ja auch bei der DNB in der Nationalbibliografie. Da steht öfter mal "[und viele weitere]" in den Beschreibungen.
Karin Kleiber (Mittwoch, 08 Juni 2016 17:01)
Eine kleine Anmerkung zu den Bezugsbedingungen:
In der D-A-CH AWR für 4.2.1.3 ist allerdings festgehalten, dass für Währungsbezeichnungen die ISO-Norm 4217 zu beachten ist – also nicht die Symbole, sondern ein Drei-Buchstaben-Code (wie sie von DNB und ÖNB schon jetzt in den Nationalbibliografien verwendet werden). Wäre es dann nicht empfehlenswert, die Beispiele statt mit Symbolen mit den Codes anzuzeigen?
Heidrun Wiesenmüller (Mittwoch, 08 Juni 2016 19:43)
Liebe Frau Kleiber,
Sie haben natürlich völlig recht - ich habe hier nicht weit genug gedacht. Um diese Beispiele an unsere Praxis anzupassen, muss in der Tat auch das geändert werden. Ich kann auch das im Wiki mal vorschlagen, kann aber natürlich nichts versprechen.
Viele Grüße
Heidrun Wiesenmüller